Cygnus を使用して Orion Context Broker と Spark Streaming を接続¶
コンテンツ :
イントロダクション¶
このドキュメントの背後にあるアイデアは、Orion Context Broker から Spark Streaming へのリアルタイムのコンテキスト情報の変更を送信する方法を、段階的に説明することです。
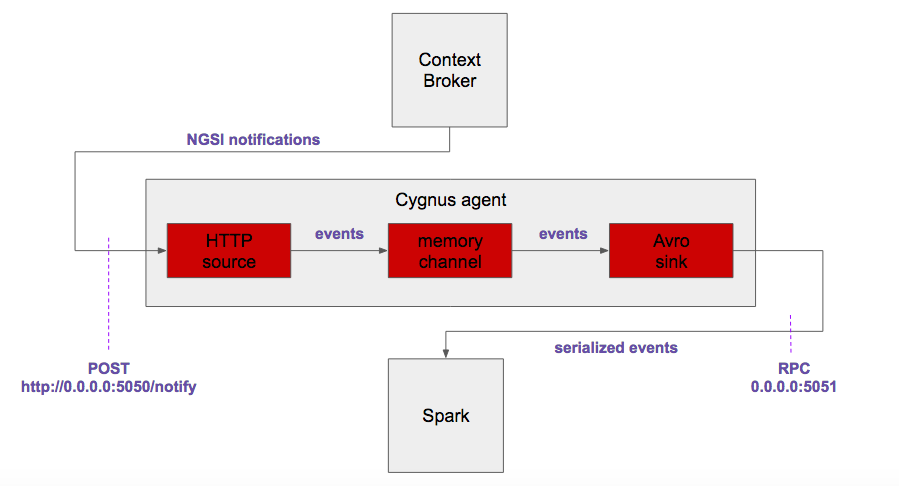
このような接続は、Cygnusのおかげで、具体的には次のコンポーネントを使用して行われます :
- Flume のネイティブ HTTP ソースで、TCP/5050ポートでリッスン
- CygnusからのカスタムNGSI REST ハンドラ
- Flumeのネイティブ・メモリチャネル
- Flumeのネイティブ Avro シンク、Avroバイナリ・イベントをTCP/5051ポートに送信
最終的なアーキテクチャは次のようになります :
このドキュメントの目的に従って、すべてのコンポーネントのインストール、構成、および実行について説明します。簡単にするために、すべてのコンポーネントが単一のローカルマシンにデプロイされます。Apache Sparkは、特にクラスタの上で動作するように設計されていますが、ローカルモードでも動作可能です。
Orion Context Broker のセットアップ¶
Orion Context Broker インストール・ガイドはこちらからご覧いただけます。少なくとも、リリース1.6.0 を使用することをお勧めします。
このインテグレーション例では、デフォルトの設定でかまいません。シェルで入力するだけで簡単に実行できます:
$ sudo service contextBroker start
Starting contextBroker... [ OK ]いつものように、Orion Context Broker が特定のコンテキスト・エンティティの更新に関する通知を Cygnus に送信するためには、サブスクリプションを行う必要があります。この例では、典型的な room1/room entity が使用されています :
$ curl -X POST "http://localhost:1026/v2/subscriptions" -s -S -H "Content-Type: application/json" -d @- <<EOF
{
"subject": {
"entities": [
{
"id": "room1",
"type": "room"
}
]
},
"notification": {
"http": {
"url": "http://localhost:5050/notify"
},
"attrsFormat": "legacy"
}
}
EOF他のコマンドを使用して、コンテキスト・エンティティが Orion に追加されます。この例では、典型的な room1/room entity エンティティが使用されています :
curl -X POST "http://localhost:1026/v2/entities" -s -S -H 'Content-Type: application/json' -d @- <<EOF
{
"id": "room1",
"type": "room",
"temperature": {
"value": 26.5,
"type": "Float"
}
}
EOF他のコマンドを使って更新しました :
curl -X POST "http://localhost:1026/v2/entities/room1/attrs" -s -S -H 'Content-Type: application/json' -d @- <<EOF
{
"temperature": {
"value": 27.5,
"type": "Float"
}
}
EOFOrion Context Broker の詳細については、Orion Context Broker の公式ドキュメントを参照してください。
Cygnus のセットアップ¶
インストールに関しては、FIWARE yum repository から行います。Cygnus エージェントを最新のバージョンにインストールしたら、次のように設定する必要があります :
$ cat /usr/cygnus/conf/agent_spark.conf
cygnusagent.sources = http-source
cygnusagent.sinks = avro-sink
cygnusagent.channels = avro-channel
cygnusagent.sources.http-source.type = http
cygnusagent.sources.http-source.channels = avro-channel
cygnusagent.sources.http-source.port = 5050
cygnusagent.sources.http-source.handler = com.telefonica.iot.cygnus.handlers.NGSIRestHandler
cygnusagent.sources.http-source.handler.notification_target = /notify
cygnusagent.sources.http-source.handler.default_service = default
cygnusagent.sources.http-source.handler.default_service_path = /
cygnusagent.sinks.avro-sink.type = avro
cygnusagent.sinks.avro-sink.channel = avro-channel
cygnusagent.sinks.avro-sink.hostname = 0.0.0.0
cygnusagent.sinks.avro-sink.port = 5051
cygnusagent.channels.avro-channel.type = memory
cygnusagent.channels.avro-channel.capacity = 1000
cygnusagent.channels.avro-channel.transactionCapacity = 100Cygnus インスタンスの設定ファイルも追加する必要があります。次のようにします :
$ cat /usr/cygnus/conf/cygnus_instance_spark.conf
CYGNUS_USER=cygnus
CONFIG_FOLDER=/usr/cygnus/conf
CONFIG_FILE=/usr/cygnus/conf/agent_spark.conf
AGENT_NAME=cygnus-ngsi
LOGFILE_NAME=cygnus.log
ADMIN_PORT=8081
POLLING_INTERVAL=30そして、サービスとして起動できます :
$ sudo service cygnus start
Starting Cygnus spark... [ OK ]Orion Context Broker と Cygnusとの統合をテストするには、単にコンテキスト・エンティティを更新し、Cygnus ログ内の関連する通知受信をチェックします :
$ tail -f /var/log/cygnus/cygnus.log
...
time=2017-01-27T13:33:28.236UTC | lvl=INFO | corr=a72db6ff-ce15-4d38-a3a3-95af2ecc73b8 | trans=a72db6ff-ce15-4d38-a3a3-95af2ecc73b8 | srv=sc_valencia | subsrv=/gardens | comp=cygnus-ngsi | op=getEvents | msg=com.telefonica.iot.cygnus.handlers.NGSIRestHandler[304] : [NGSIRestHandler] Received data ({ "subscriptionId" : "51c0ac9ed714fb3b37d7d5a8", "originator" : "localhost", "contextResponses" : [ { "contextElement" : { "attributes" : [ { "name" : "temperature", "type" : "centigrade", "value" : 26.5 } ], "type" : "room", "isPattern" : "false", "id" : "room1" }, "statusCode" : { "code" : "200", "reasonPhrase" : "OK" } } ]})
...このインテグレーションの瞬間には、Spark に接続できないという Java の例外がいくつか見受けられます。TCP/ 5051 ポート上の Spark リスナーはまだ実行されていないので、これは正常です。
Spark Streamingのセットアップ¶
Apache Sparkは、Spark Download ページで入力した URL からインストールされ、以下を選択します :
- Spark リリース : 1.6.3
- パッケージタイプ : Hadoop 2.3 用に事前ビルド済み
- ダウンロードタイプ : 直接ダウンロード
"download Spark" リンクが指し示す URL をコピーして、例えば、自分のマシンのホームディレクトリにダウンロードする必要があります。 あなたのケースでは、d3kbcqa49mib13.cloudfront.net を実際のベース URL に置き換えてください :
$ cd ~
$ wget http://d3kbcqa49mib13.cloudfront.net/spark-1.6.3-bin-hadoop2.3.tgz
--2017-01-18 14:40:31-- http://d3kbcqa49mib13.cloudfront.net/spark-1.6.3-bin-hadoop2.3.tgz
Resolviendo d3kbcqa49mib13.cloudfront.net (d3kbcqa49mib13.cloudfront.net)... 54.240.186.114, 54.240.186.149, 54.240.186.159, ...
Conectando con d3kbcqa49mib13.cloudfront.net (d3kbcqa49mib13.cloudfront.net)[54.240.186.114]:80... conectado.
Petición HTTP enviada, esperando respuesta... 200 OK
Longitud: 273211089 (261M) [application/x-tar]
Grabando a: “spark-1.6.3-bin-hadoop2.3.tgz”
100%[===========================================================================================================================================>] 273.211.089 30,8MB/s en 9,6s
2017-01-18 14:40:40 (27,3 MB/s) - “spark-1.6.3-bin-hadoop2.3.tgz” guardado [273211089/273211089]ダウンロードしたファイルを解凍して削除する必要があります :
$ tar xzf spark-1.6.3-bin-hadoop2.3.tgz
$ rm spark-1.6.3-bin-hadoop2.3.tgzさて、Spark は、ホームディレクトリ下で利用可能になるはずですので、ディレクトリを変更しましょう :
$ cd spark-1.6.3-bin-hadoop2.3総合テスト¶
リアルタイム・コンテキスト情報解析のアーキテクチャ全体をテストするために、Sparkが JavaFlumeEventCount というサンプル内で提供する、すでに開発された解析アプリケーションを使用します :
$ ls examples/src/main/java/org/apache/spark/examples/streaming/ | grep JavaFlumeEventCount.java
JavaFlumeEventCount.javaJavaFlumeEventCount は、設定されたポートで受信した Avro イベントの数を単純に数えます。このようなアプリケーションは Spark の run-example スクリプトを使って実行します :
$ ./bin/run-example streaming.JavaFlumeEventCount 0.0.0.0 5051
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/01/18 14:46:26 INFO StreamingExamples: Setting log level to [WARN] for streaming example. To override add a custom log4j.properties to the classpath.
17/01/18 14:46:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-------------------------------------------
Time: 1484750792000 ms
-------------------------------------------
Received 0 flume events.ご覧のように、Avro イベントは読み取られません。それにもかかわらず、サブスクライブしているものの中からあるコンテキスト・エンティティを更新すると、アプリケーションがそれを受け取ることがわかります。初回は数秒かかるはずです:
-------------------------------------------
Time: 1484750800000 ms
-------------------------------------------
Received 1 flume events.詳細情報¶
この後、ユーザは、NGSI コンテキスト情報を含むバイナリ Avro イベントに基づいて、Spark Streaming のための独自の分析を作成する必要があります。
FIWARE C osmos repository のライブラリとしてバンドルされた Spark 用の NGSI 固有の関数を使用することを強くお勧めします。このようなライブラリには、バイナリ Avro イベントをデシリアライズするためのプリミティブ、コンテキスト・エンティティモデルに適合したタプル(tuples)の使用などがあります。また、FIWARE 開発者を確実にサポートし、Spark の上に NGSI ライクのアナリティクスの設計を簡素化します。