NGSIDynamoDBSink¶
コンテンツ :
機能性¶
com.iot.telefonica.cygnus.sinks.NGSIDynamoDBSink、または単なる NGSIDynamoDBSink は、Amazon Web Services の DynamoDB データベース内で NGSI ライクのコンテキストデータ・イベントを維持するように設計されたシンクです。通常、このようなコンテキストデータは、Orion Context Broker インスタンスによって通知されますが、NGSI言語を話す他のシステムである可能性があります。
データジェネレータとは無関係に、NGSI コンテキストデータは常に Cygnus ソースの内部オブジェクト NGSIEvent に変換されます。最終的には、これらのイベント内の情報を、特定の DynamoDB データ構造にマップする必要があります。
次のセクションでこれについて詳しく説明します。
NGSIEvent オブジェクトへの NGSI イベントのマッピング¶
コンテキストデータを含む、通知された NGSI イベントは、NGSI データジェネレータまたは永続化される最終的なバックエンドとは無関係に、NGSIEvent オブジェクトに変換されます。(各コンテキスト要素a NGSIEventが作成され、このようなイベントは、特定のヘッダと ContextElement オブジェクトを組み合わせたものです。
これは、NGSIRestHandler のおかげで、cygnus-ngsi Http のリスナー(Flume jergon のソース)で行われています。翻訳されると、データ(NGSIEvent オブジェクトとして)は、今後の消費のために内部チャネルに入れられます。次のセクションを参照してください。
DynamoDB データ構造への NGSIEvents のマッピング¶
DynamoDB は、データ項目のテーブルにデータを編成します。すべてのテーブルは、同じデフォルトデータベース、つまり Amazon Web Services のユーザ空間に配置されています。そのような機構は、NGSIEvent が永続化されるたびに NGSIDynamoDBSink によって利用されます。
DynamoDB データベースの命名規則¶
前述のように、Amazon ユーザごとに DynamoDB データベースがあります。これらのユーザの名前は、+, =, ,, ., @, _, - の共通文字を含む英数字である必要があります。これにより、特定のエンコーディングが適用されます。
DynamoDB databases name length データベースの名前の長さは、最小3文字、最大255文字です。
シンクの現在のバージョンはマルチテナンシーをサポートしていません。つまり、Amazonのユーザ空間したがってデータベースのみを使用できます。そのようなユーザスペースは構成で指定されています。構成セクションを確認してください。したがって、Amazon のユーザ空間名と FIWARE service path が完全に一致する必要はありません。それにもかかわらず、シンクの将来のバージョンでマルチテナンシーが実装される予定です。その場合、各サービスデータを適切な Amazo nユーザに正しくルーティングするために、FIWARE service と Amazon のユーザスペース名の両方が一致することが必須となります。
DynamoDB テーブルの命名規則¶
これらのテーブルの名前は、設定されたデータモデルによって異なります。詳細については、構成セクションを参照してください :
- サービスパスによるデータモデル(data_model=dm-by-service-path)。データモデル名が示すように、通知された FIWARE service path または
NGSIRestHandlerでデフォルトで設定されたものがテーブルの名前として使用されます。これにより、同じサービスパスに属するすべての NGSI エンティティに関するデータがこの一意のテーブルにストアされます。このデータモデルに関する唯一の制約は、FIWARE service path をルート(/)にすることができないことです - 実体によるデータモデル(data_model=dm-by-entity)。各エンティティに対して、通知された/デフォルトの FIWARE service path は、通知されたエンティティ ID とエンティティ・タイプに連結され、テーブル名を構成します。FIWARE service path がルートディレクトリ(
/)である場合、エンティティ ID とタイプのみが連結されます
どちらの場合も、通知された/デフォルトの FIWARE service はテーブル名の前に置かれます。
DynamoDB は、英数字と _, -, . だけを受け入れます。これにより、特定のエンコーディングが適用されます。
DynamoDB テーブルの名前の長さは、最大255文字(最小、3文字)です。
次の表は、テーブル名の構成をまとめたものです :
| FIWARE service path | dm-by-service-path |
dm-by-entity |
|---|---|---|
/ |
<svc>x002f |
<svc>xffffx002fxffff<entityId>xffff<entityType> |
/<svcPath> |
<svc>xffffx002f<svcPath> |
<svc>xffffx002f<svcPath>xffff<entityId>xffff<entityType> |
エンティティ ID とタイプの連結が、NGSIEvent 内のグループ化ルールの使用するかどうかに応じて、notified_entities/grouped_entities ヘッダ値ですでに指定されていることを確認してください。、詳細については構成セクションを参照してください。
行ライクのストア (Row-like storing)¶
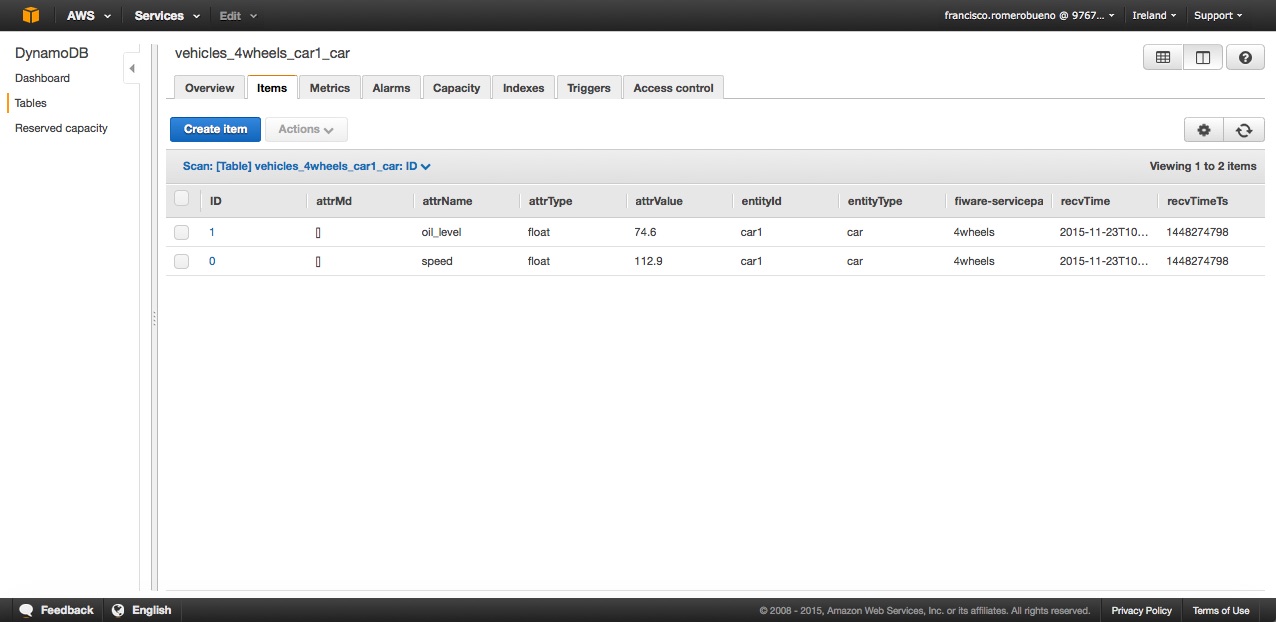
リソースに関連付けられたデータストア内にストアされている特定のデータに関して、attr_persistence パラメータが row (デフォルトのストアモード)に設定されている場合、通知されたデータは属性ごとにストアされ、それぞれのインサートを構成します。各インサートには次のフィールドがあります :
recvTimeTsUTC: タイムスタンプ(ミリ秒単位)recvTime: 人間が判読可能な形式のUTCタイムスタンプ(ISO 8601)。fiwareServicePath: 通知された fiware-servicePath、または通知されない場合はデフォルトの設定済みパスentityId: 通知されたエンティティ IDentityType: 通知されたエンティティタイプattrName: 通知された属性名attrType: 通知された属性タイプattrValue: 最も単純な形式では、この値は単なる文字列ですが、Orion 0.11.0 以降、Json オブジェクトまたは Json 配列になる可能性がありますattrMd: これには、Json の属性のメタデータ配列の文字列のシリアル化が含まれます。属性にメタデータがない場合、空の配列[]が挿入されます
列ライクのストア (Column-like storing)¶
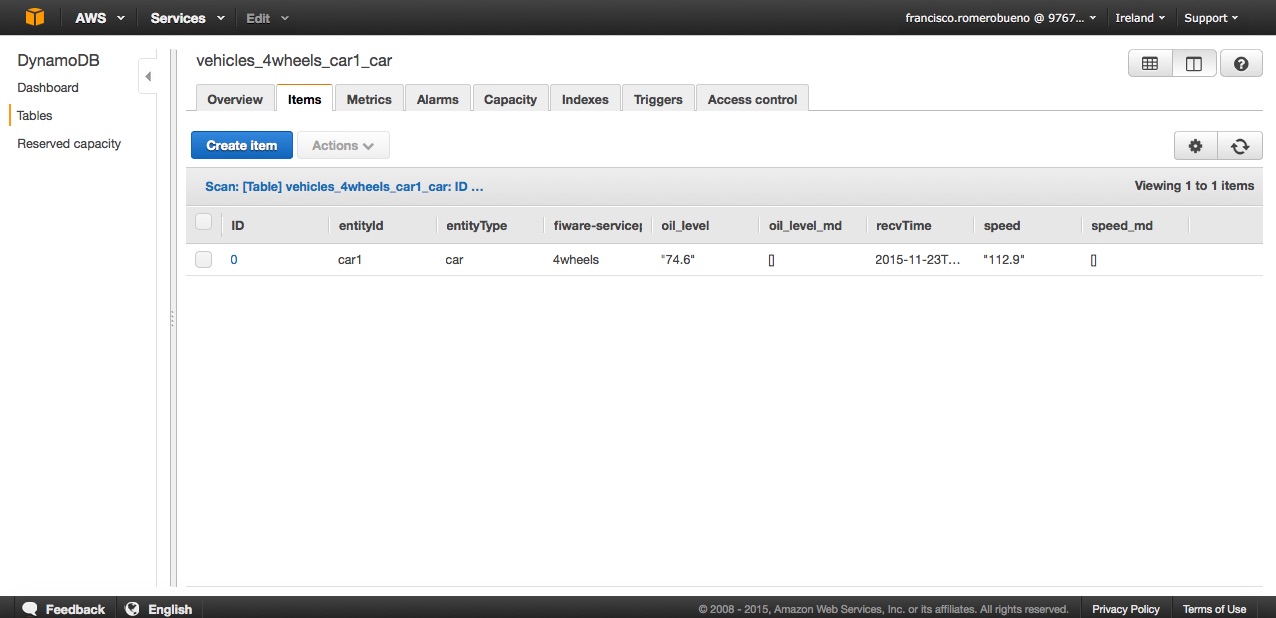
リソースに関連付けられたデータストア内にストアされている特定のデータに関して、attr_persistence パラメータが column に設定されている場合は、通知されたエンティティ全体に対して、次のフィールドを含む単一のラインが作成されます :
recvTime: 人間が判読可能な形式のUTCタイムスタンプ (ISO 8601)fiwareServicePath通知された パス、または デフォルトのパスentityId: 通知されたエンティティ IDentityType: 通知されたエンティティタイプ- 通知された属性ごとに、属性として指定されたフィールドが考慮されます。このフィールドには、時間に沿って属性値が格納されます
- 通知された属性ごとに、属性名と
_mdの連結として指定されたフィールドが考慮されます。このフィールドには、属性のメタデータ値が時間とともにストアされます
例¶
NGSIEvent¶
以下の NGSIEvent が通知された NGSI コンテキストデータから作成されたと仮定します。以下のコードは実体データ形式ではなくオブジェクト表現です :
ngsi-event={
headers={
content-type=application/json,
timestamp=1429535775,
transactionId=1429535775-308-0000000000,
correlationId=1429535775-308-0000000000,
fiware-service=vehicles,
fiware-servicepath=/4wheels,
<grouping_rules_interceptor_headers>,
<name_mappings_interceptor_headers>
},
body={
entityId=car1,
entityType=car,
attributes=[
{
attrName=speed,
attrType=float,
attrValue=112.9
},
{
attrName=oil_level,
attrType=float,
attrValue=74.6
}
]
}
}テーブル名¶
DynamoDB テーブル名は、構成されたデータモデルに応じて次のようになります :
| FIWARE service path | dm-by-service-path |
dm-by-entity |
|---|---|---|
/ |
vehicles |
vehiclesxffffx002fxffffcar1xffffcar |
/4wheels |
vehiclesxffffx002f4wheels |
vehiclesxffffx002f4wheelsxffffcar1xffffcar |
行ベースのストア (Raw-based storing)¶
テーブル名 x002fvehiclesxffff4wheelsxffffcar1xffffcar (エンティティによるデータモデル、非ルートサービスパス)と構成パラメータとして attr_persistence=row を想定しましょう。このテーブルにストアされるデータは次のとおりです :
列ベースのストア (Column-based storing)¶
attr_persistence=colum の場合は、NGSIDynamoDBSink は、次のように本文内のデータを永続化します :
管理者ガイド¶
構成¶
NGSIDynamoDBSink は、次のパラメータによって構成されます :
| パラメータ | 必須 | デフォルト値 | コメント |
|---|---|---|---|
| type | yes | N/A | com.telefonica.iot.cygnus.sinks.NGSIDynamoDBSink である必要があります |
| channel | yes | N/A | |
| enable_grouping | no | false | true または false。詳細については、このリンクをチェックしてください |
| enable_name_mappings | no | false | true または false。詳細については、このリンクをチェックしてください |
| enable_lowercase | no | false | true または false |
| data_model | no | dm-by-entity | dm-by-entity または dm-by-service-path |
| attr_persistence | no | row | row または column |
| access_key_id | yes | N/A | アカウントを作成する際にAWSが提供 |
| secret_access_key | yes | N/A | アカウントを作成する際にAWSが提供 |
| region | no | eu-central-1 | AWSのリージョン |
| batch_size | no | 1 | 永続かの前に蓄積されたイベントの数。最大25。詳細については、Amazon Web Servicesのドキュメントを参照してください |
| batch_timeout | no | 30 | バッチがそのまま永続化される前に構築される秒数 |
| batch_ttl | no | 10 | バッチを永続化できない場合のリトライ回数。リトライしない場合は 0、無限にリトライする場合は -1 を使用してください。無限のTTL(非常に大きいものでさえ)がすべてのシンクのチャネル容量を非常に素早く消費するかもしれないと考えてください |
| batch_retry_intervals | no | 5000 | 永続化されていないバッチに関するリトライが行われるコンマ区切りの間隔(ミリ秒単位)のリスト。最初のリトライは、最初の値と同じ数ミリ秒後に実行され、2回目の再試行は2番目の値の後に完了します。batch_ttl が間隔の数より大きい場合、最後の間隔が繰り返されます |
構成例は次のとおりです :
cygnus-ngsi.sinks = dynamodb-sink
cygnus-ngsi.channels = dynamodb-channel
...
cygnus-ngsi.sinks. dynamodb-sink.type = com.telefonica.iot.cygnus.sinks.NGSIDynamoDBSink
cygnus-ngsi.sinks.dynamodb-sink.channel = dynamodb-channel
cygnus-ngsi.sinks.dynamodb-sink.enable_grouping = false
cygnus-ngsi.sinks.dynamodb-sink.enable_lowercase = false
cygnus-ngsi.sinks.dynamodb-sink.enable_name_mappings = false
cygnus-ngsi.sinks.dynamodb-sink.data_model = dm-by-entity
cygnus-ngsi.sinks.dynamodb-sink.attr_persistence = column
cygnus-ngsi.sinks.dynamodb-sink.access_key_id = xxxxxxxx
cygnus-ngsi.sinks.dynamodb-sink.secret_access_key = xxxxxxxxx
cygnus-ngsi.sinks.dynamodb-sink.region = eu-central-1
cygnus-ngsi.sinks.dynamodb-sink.batch_size = 25
cygnus-ngsi.sinks.dynamodb-sink.batch_timeout = 30
cygnus-ngsi.sinks.dynamodb-sink.batch_ttl = 10
cygnus-ngsi.sinks.dynamodb-sink.batch_retry_intervals = 5000ユースケース¶
[比較的優れたスループット](http://docs.aws.amazon.com/
amazondynamodb/latest/developerguide/ProvisionedThroughputIntro.htmlとスケーラブルなストレージを備えたクラウドベースのデータベースを探している場合に NGSIDynamoDBSink を使用します。
重要なメモ¶
テーブルタイプとそのグループ化ルールとの関係¶
見られるように、テーブルタイプ構成パラメータは、データの直接集計のためのメソッドです。デフォルトの宛先によって、同じエンティティに関するすべての通知は、同じ DynamoDB テーブルに格納されます)または、デフォルトの service-path によって、同じサービスパスに関するすべての通知は、同じDynamoDBテーブル内に格納されます。
グループ化機能は別の集約メカニズムですが、間接的な機能です。つまり、グループ化機能は実際にはデータを単一のテーブルに集約するわけではありません。つまり、シンクは構成済みのテーブルタイプ(上記参照)に基づいて行われますが、デフォルトの宛先またはサービスパスが変更され、データが最終的に集計されるかどうかは、テーブルの種類によって異なります。
たとえば、選択されたテーブルタイプが宛先であり、グループ化機能が有効になっていない場合、2つの異なるエンティティデータである 'car' タイプの 両方の car1 と car2 は、デフォルトの出力先に従って、car1_car と car2_car がそれぞれ、2つの異なる DynamoDB テーブルに永続化されます。ただし、"car タイプのすべての車に cars という名前の変更された目的地がある"というグループ化ルールが有効になっていると、両方のエンティティデータが cars という単一のテーブルに永続化されます。この例では、直接集約は宛先別にテーブルタイプによって決定されますが、間接的にグループ化ルールによっても集約を決定しています。
永続化モード¶
同じ数の属性が通知されるとは限りません。これは、NGSI ライクの送信者へのサブスクリプションに依存します。この種類のデータベースは、同じテーブル内の異なる長さのアイテムを永続化するために設計されているため、DynamoDB では問題ありません。とにかく、それは考慮に入れる必要があります、あなたのアプリケーションを設計するとき、row 永続化モードは、通知された各属性のための固定8フィールド(fixed 8-fields)のデータ項目を常に挿入します。columnモードは、既に説明したように、長さの異なるいくつかのデータ項目(フィールドの意味で)の影響を受ける可能性があります。
バッチ処理¶
プログラマ・ガイドで説明したように、NGSIDynamoDBSink は、内部 Flume チャネルからイベントを収集するための組み込みのメカニズムを提供する NGSISink を拡張します。このメカニズムにより、拡張クラスは、最終的なバックエンドにおけるこのような一連のイベントの永続化の詳細のみを処理することができます。
バッチのメカニズムに関して重要なことは、インサートの数が大幅に減少するため、シンクの性能を大幅に向上させることです。例を見てみましょう。100個の NGSIEvent を一組としましょう。最良の場合、これらのイベントはすべて同じエンティティに関係します。つまり、その中のすべてのデータが同じ DynamoDB テーブルに保持されます。イベントを1つずつ処理する場合は、DynamoDB に100個のインサートが必要です。それにもかかわらず、この例では、1つのインサートのみが必要です。明らかに、すべてのイベントが常に同じユニークなエンティティを考慮するとは限らず、多くのエンティティがバッチ内に関与する可能性があります。しかし、これは問題ではありません。イベントのいくつかのサブバッチがバッチ内に作成されるため、最終的な出力先の DynamoDB テーブルごとに1つのサブバッチが作成されるためです。 最悪の場合、100のエンティティは100種類のエンティティ(100個の異なるDynamoDBテーブル)になりますが、これは通常のシナリオではありません。したがって、1バッチあたり10〜15個のサブバッチが現実的であると仮定すると、10〜15個のインサートのみを用いたイベントアプローチによるイベントの100個のインサートを置き換えます。
バッチ処理メカニズムは、新しいデータが到着しないときにシンクがバッチ構築の待ち状態にとどまるのを防ぐために蓄積タイムアウトを追加します。 そのようなタイムアウトに達すると、バッチはそのまま維持されます。
永続化されていないバッチのリトライに関しては、2つのパラメータが使用されます。一方は、Cygnus がイベントを確実にドロップする前にリトライする回数を指定して、Time-To-Live(TTL) を使用します。もう一方は、リトライ間隔のリストを構成することができます。そのようなリストは最初のリトライ間隔を定義し、次に2番目のリトライ間隔を定義します。TTLがリストの長さより大きい場合、最後のリトライ間隔が必要な回数繰り返されます。
デフォルトで、NGSIDynamoDBSink は、設定されたバッチサイズは1で、バッチ蓄積タイムアウトは30秒です。それにもかかわらず、上で説明したように、パフォーマンス目的で少なくともバッチサイズを増やすことを強くお勧めします。どのような最適な値ですか?バッチのサイズは、イベントが得られているチャネルのトランザクションサイズに密接に関連しています(最初のものが2番目のものより大きいことは意味がありません)。また、推定されたサブバッチの数にも依存します。累積タイムアウトは、最終ストレージに新しいデータを出力する頻度に依存します。イベントのバッチとその適切なサイジングについての深い議論は、パフォーマンスのドキュメントで見つけることができます。
DynamoDB のスループット¶
DynamoDB は、テーブルが作成される領域の長さと書き込みあたりの情報の量によって、スループットに重大な影響を与えるクラウドベースのストレージです。
リージョンに関しては、常に Cygnus と NGSIDynamoDBSink を実行しているホストに最も近いものを選択してください。
書き込みあたりの情報量については、AWS DynamoDB での書き込み、および読み込みのために予約された容量を細かく調整する方法について、このドキュメントをよくお読みください。書き込み、または読み取り機能を増やすことでサービスのコストも増加することに注意してください。
エンコーディング¶
Cygnusは、DynamoDB データ構造に合わせてカスタマイズされたこの特定のエンコーディングを適用します :
- 英数字はエンコードされません
- 数字はエンコードされません。
- アンダースコア文字(
_)はエンコードされません - ハイフン文字(
-)はエンコードされません - ドット文字(
.)はエンコードされません - 等号文字(
=)は、xffffとしてエンコードされます。 - FIWARE service paths のスラッシュを含む他のすべての文字は、Unicode 文字の
x文字としてエンコードされます x文字と Unicode で構成されるユーザ定義の文字列は、Unicodeの後にxxとしてエンコードされますxffffは、連結文字として使用されます
プログラマ・ガイド¶
NGSIDynamoDBSink クラス¶
他の NGSI ライクのシンクと同様に、NGSIDynamoDBSink、NGSISink ベースを拡張します。拡張されるメソッドは次のとおりです :
void persistBatch(Batch batch) throws Exception;Batch には 通知されたコンテキストデータイベントを解析した結果である NGSIEvent オブジェクトのセットが含まれます。バッチ内のデータは宛先別に分類され、最終的に宛先はデータが永続化されるDynamoDBテーブルを指定します。したがって、各宛先は、どの DynamoDBBackend 実装でも永続化される宛先データ文字列を構成するために反復されます。
public void start();DynamoDBBackend の実装が作成されます。起動するシーケンスは NGSIDynamoDBSink() (コンストラクタ)、configure() および、start() であるため、start() メソッドではなくコンストラクタで行う必要があります。
public void configure(Context);上記のような完全な構成が、与えられた Context インスタンスから読み取られます。
認証と認可¶
NGSIDynamoDBSink の現在の実装は、AWS アクセスキー・メカニズムに依存しています。